# Building production machine learning applications
Gartner statistics show that on average it takes companies two years to get from pilot to live, as there can be many hidden complexities. By using Kortical, customers are seeing it take from 5 weeks to 6 months to build full machine learning solutions from scratch. There is a huge range and diversity of types of deployment of production applications and services.
The main topics covered here are:
- Meeting SLAs - automatic failover and recovery, redundancy, hardware isolation
- Multiple deployments - data-science, development separation
- Model maintenance
- Production architectures with Cloud API
- Audit trail
# Meeting SLAs
Any production system needs to be reliable. Kortical is powering critical systems for Deloitte and the NHS and can meet strict SLAs. This is due to having multiple redundancy for hosted models, automatic failover and recovery.
In addition, Kortical offers hardware isolation and the CPU and memory specifications can all be set per deployment or shared between deployments as desired. To configure this please contact Kortical support.
# Multiple deployments & environment separation
A prerequisite for almost any system is that development changes are managed separately from production. To support this Kortical, supports multiple deployment environments. The defaults are:
- Integration - for development
- UAT - for user acceptance testing
- Production - for the live system
A model can be promoted from one deployment to another via a click on publish.
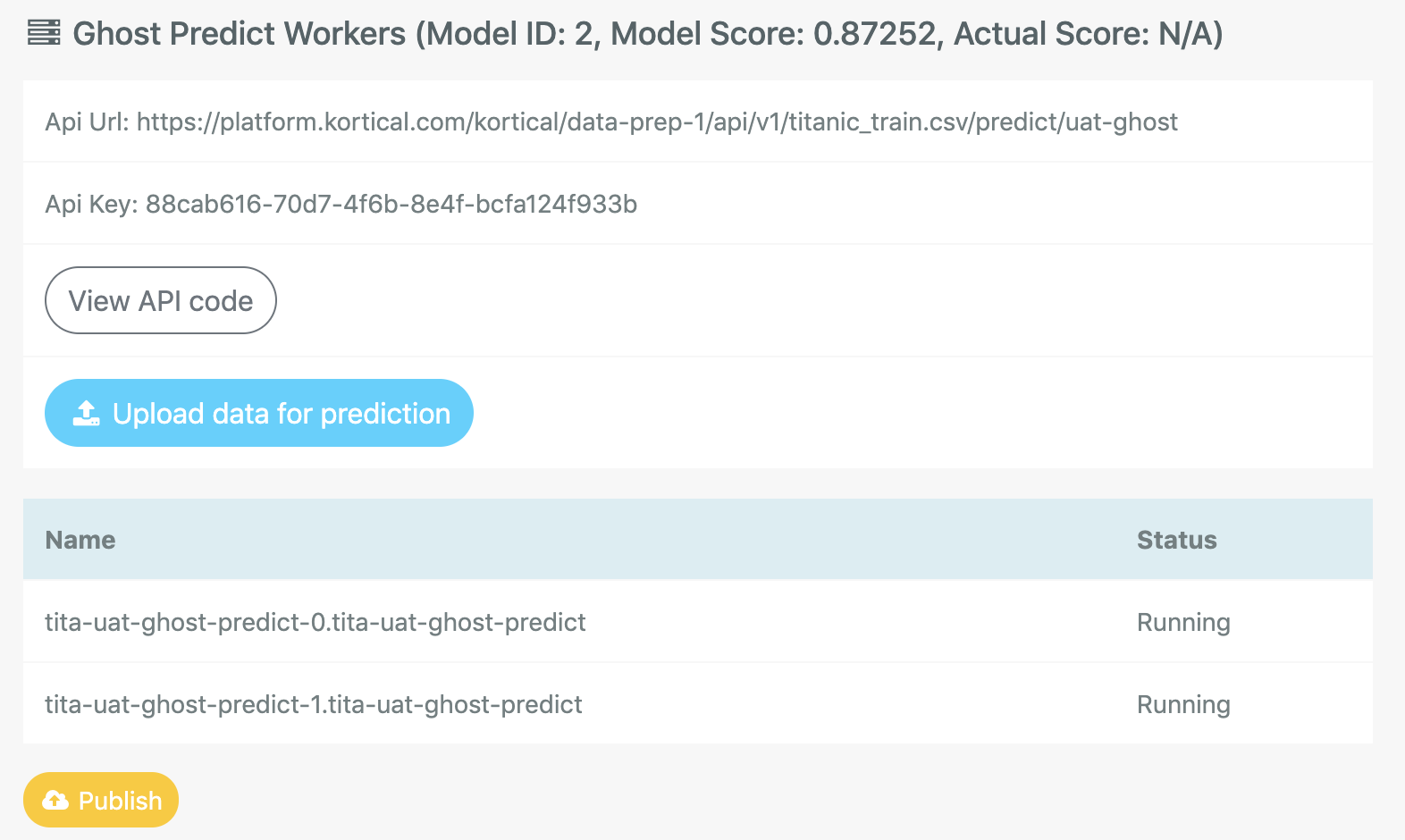
By default the challenger model for a deployment is the live model from the deployment below. The challenger model is hosted and accessible via a separate API. This allows us to be able to operate both challenger and incumbent models simultaneously and either:
- Back test the new model - use a held back set of results to validate that the challenger model does indeed perform better
- Shadow test the new model - by scoring how it differed to the live model and tracking the results
- Canary test the new model - by sending a small portion of requests that way
Code calls into a deployment via an API that’s fixed for the deployment, for example:
https://platform.kortical.com/kortical/company_name/api/v1/model_name/predict/production
New models can be published to a deployment and seamlessly replace existing models with zero downtime. The key advantages of this approach are:
- New model updates can happen separately from new code deployments, except where there are changes in the nature of the data
- Data-scientists aren’t beholden to the code team to get new releases out
- Model updates can happen much more frequently than code releases
- Models can be replaced with zero downtime
- Routine model retraining from new data to deal with model drift can be automated
Each deployment has its own keys to limit access for predictions and other operations. This methodology for the interaction of code, models, deployments and APIs is unique to Kortical and patent pending.
# Model maintenance
Customer, market and system changes are all reasons that model performance can drop. Other factors such as increasing volumes of data might allow us to create new, better models. For all these reasons, we may want to update our live models over time.
There are two types of model update:
- Adding new data in the same format to see if performance can be improved
- Adding feature engineering or new data in a different format to see if performance can be improved
The second approach is similar to the model building process, so does not warrant too much in depth discussion. The first process is more interesting in that typically this would take quite a lot of manual effort, but with Kortical this can be fully automated by:
- Storing off new data as it comes in
- Using the API to upload it to the platform
- Kicking off training
- Publishing a new model to a parallel deployment
- Running tests to validate the model
- Publishing this live
We’re looking for customers to join the Beta programme for the self learning ML models, so if this is of interest please let us know.
# Production architectures with Cloud API
We touched on the Cloud API previously in the piloting phase. However, it is not just a place to host toy applications - it is a robust Kubernetes environment with added layers of automation. It is capable of hosting microservice architectures of any complexity, from small single service web apps to complex distributed systems processing huge volumes of data daily while still meeting strict SLAs. The Kortical Cloud API is in use by our largest enterprise customers.
# Audit trail
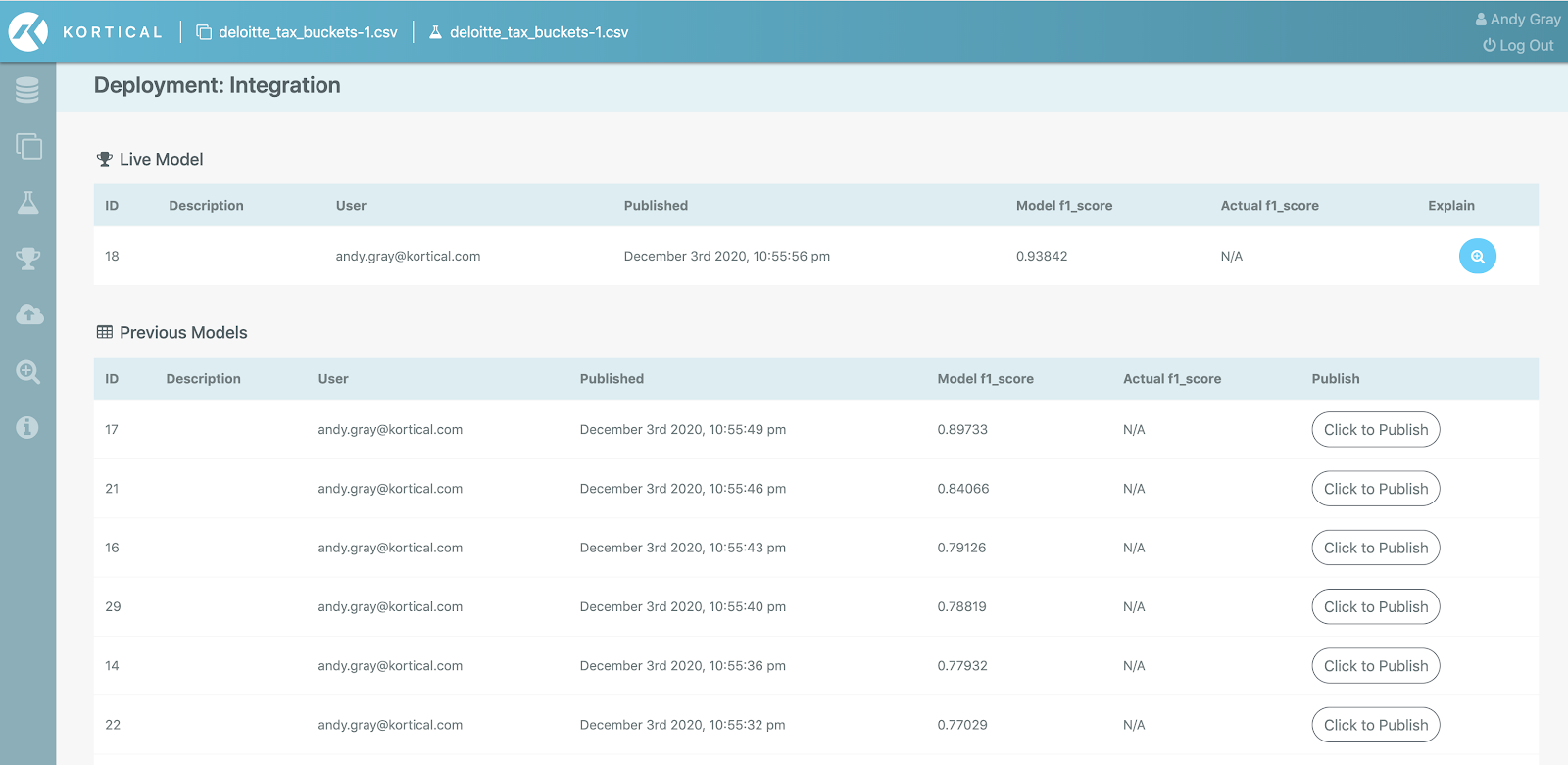
Another prerequisite for many highly regulated industries is an audit trail. This has been true for financial institutions for a long time but with GDPR someone would have the right to query why they were targeted with a specific marketing message. To answer this we need a log of every model published to every deployment and the ability to query them about any prediction.
Kortical has a full audit history for every deployment, available as described here:
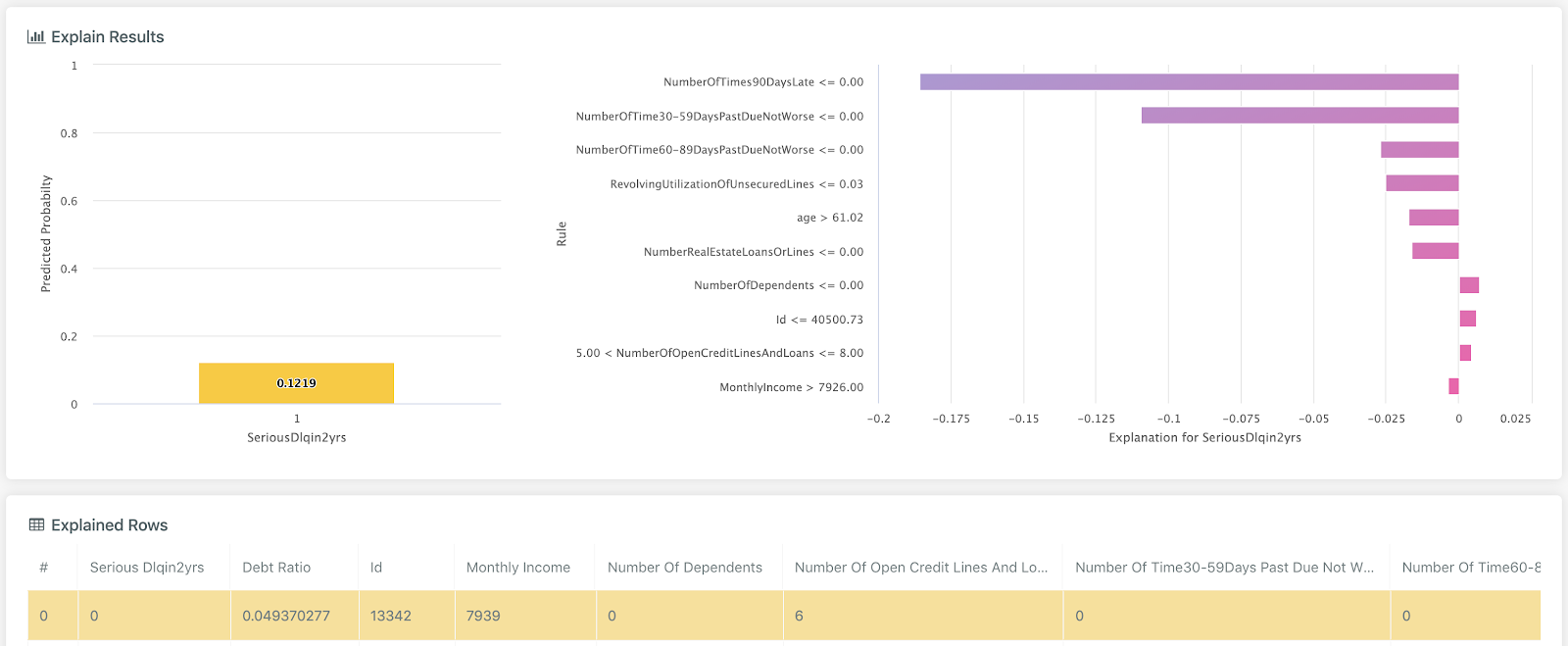
In addition, for every historical model we can get the explanation for a given prediction. Below is an example of a credit decision model, explaining the main factors of why this person was a given a 12% likelihood of serious delinquency in the next 2 years.
# Summary
There is such a variety of ways to approach productionised machine learning solutions. This section has touched on just a few key ways Kortical facilitates that. If there are any other aspects of production machine learning solutions you would like to see covered, please do reach out to us.