# kortical.api.superhuman_calibration
# What is Superhuman Calibration?
Superhuman Calibration is the cornerstone of what we call Superhuman Automation: artificial intelligence which can perform a task at human accuracy or above.
Consider a classification task which is carried out entirely by humans, where the level of accuracy is 80%. Having built and optimised a model, we find that its accuracy is only 70% across the whole dataset; this is lower than the current human-driven process. Most businesses are only willing to automate a task if it surpasses human accuracy, be this for regulatory or customer experience purposes; this is a critical reason why currently 85% of AI projects are considered failures. On the other hand, crossing the superhuman boundary leads to typically 70% - 95% automation of a business function.
Using Superhuman Calibration, we identify a large subset of data where the ML classifier achieves an accuracy of 95%, which is better than humans by 15%. Although the classifier operates on slightly less data (80% automation of the entire task), it performs at superhuman accuracy, so is now feasible for businesses to automate. The following diagram represents the situation before and after applying calibration.
| Before calibration (not superhuman, not feasible) | After calibration (superhuman and feasible!) |
|---|---|
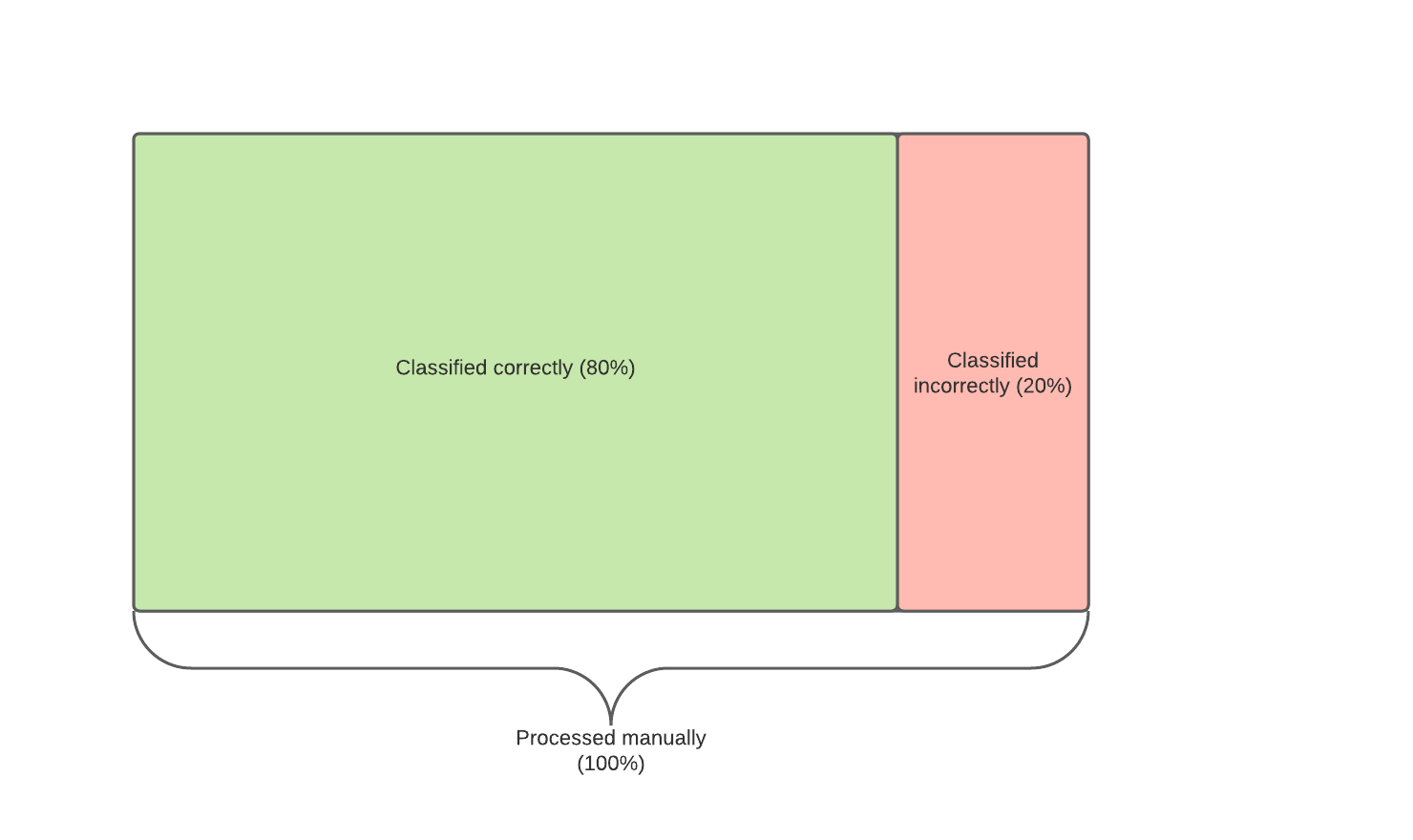 | 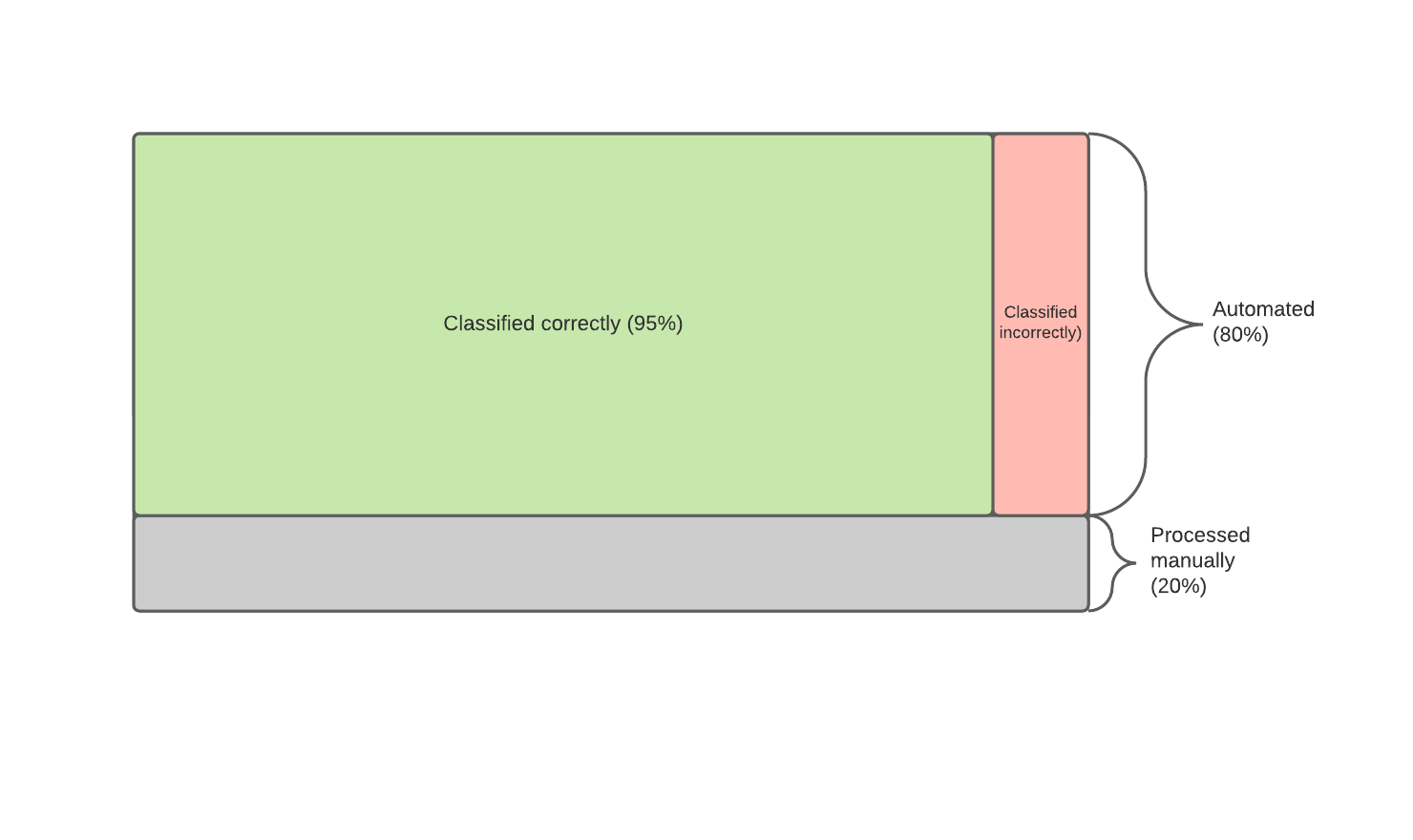 |
Having calibrated, we can now introduce automation into the process: 80% of all classifications are made by the model, and only 20% of classifications are manual (the subset of data that ML could not address confidently). Wherever the model does make predictions, it does so with better accuracy than humans. Furthermore, Superhuman Automation will be possible for a higher proportion of cases as more training data is collected over time.
Quite simply, Superhuman Calibration allows us to improve ML by identifying a subset of tasks where a model can perform at superhuman levels. This key technology is wrapped with various tools and processes to form Kortical's Superhuman Automation approach, which allows experienced domain experts to keep improving their AI over time and help it adapt to new types of data.
# How does it work?
Many people think of yhat_probs as a synonym for true probability; while they are definitely correlated, we cannot choose a target confidence of 0.7 and expect to be right 70% of the time. We also have to account for the density of observations for various yhat values, non-linearities that this introduces as well as interplay with the other classes and their thresholds. In this optimisation step we find individual thresholds for each class that allows us to best achieve the overall goal.
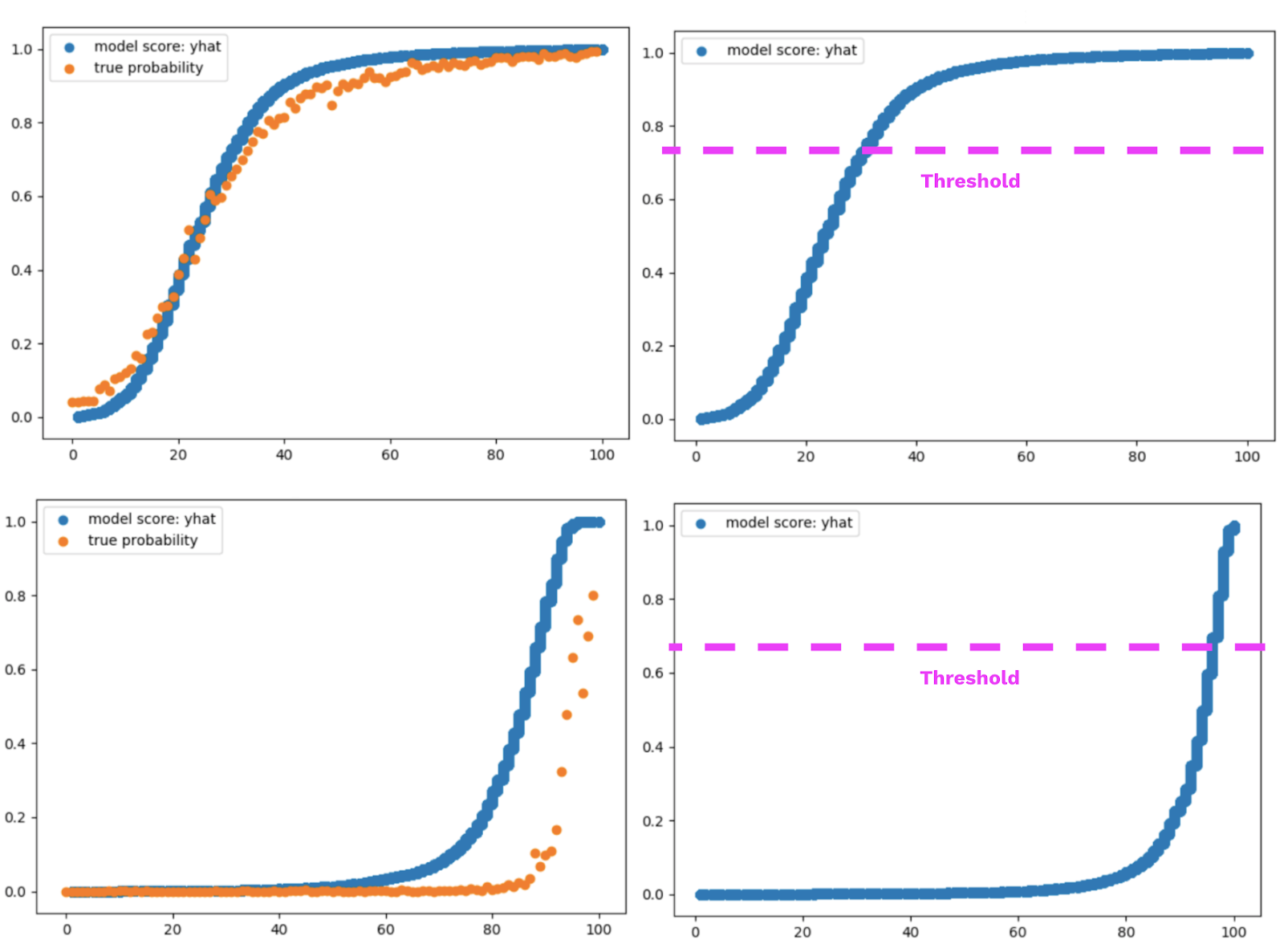
Our approach is to split the test set in two to create a calibration set and a test set, we can then run an optimiser to find the thresholds for the various classes that allow us to hit the desired target accuracy level. We then test these thresholds on the test set to prove that they generalise to new data, and to also understand the likely error bounds.
Wherever the thresholds are not met, we return a not automated or for review class in place. This may be an existing class or a new class that we introduce in this step.
# calibrate
This function calibrates thresholds such that the overall automated accuracy associated with the calibration set is as close to the target accuracy as possible. Where important classes are given, the precisions associated with these classes are also as close to the target accuracy as possible.
Inputs
df_fit- The dataset on which the thresholds should be fit.targets- A string, the name of the target to be predicted, or a list of strings in the multi-label setting.target_accuracy- The desired overall (automated) accuracy that should be achieved upon tuning thresholds, as well as the desired (class-specific) precision(s) that should be achieved for the important class(es). Should be given as a float between 0 and 1.non_automated_class(= None) - The label which should represent the decision not to automate a row, given as a string. This may or may not be a label that appears as a label in the training set. This parameter must be specified in the case of a binary classification problem, and must be one of the two labels for the corresponding target.important_classes(= None) - A string or list of strings representing important classes that should have individual thresholds tuned for them. These thresholds are tuned before the generic thresholds to ensure that the important classes have the correct accuracy associated with them. If given as a list, the important classes should be given in order of most important to least important (a determining factor in the order the thresholds are tuned and how certain predictions are handled, depending upon theimportant_classes_strategy).important_classes_strategy- An enum specifying a strategy to use to handle predictions where two or more important classes meet their thresholds.
Returns
A dictionary containing all the information that is needed to apply these thresholds to data, and should be passed as the second argument to superhuman_calibration.apply.
Raises
ValueError: Raised whenever df_fit represents a binary classification problem, but non_automated_class is not specified. (it must be set to one of the two classes seen in the target column.)
from kortical.api import superhuman_calibration
calibration_data = superhuman_calibration.calibrate(df_fit,
targets,
target_accuracy,
non_automated_class=None,
important_classes=None,
important_classes_strategy=ImportantClassesStrategy.max_yhat_in_important_classes)
# apply
This function applies thresholds (tuned in the calibrate function) to a dataset, yielding predictions utilising the given important class strategy.
Inputs
df- The dataframe on which to apply thresholds. This should contain the relevantyhat_probscolumns.calibration_data- the thresholds that you wish to apply; this is the dictionary returned fromsuperhuman_calibration.calibrate(see above).in_place(= False) - Determines whether to modify the input dataframe (df) in place. By default, a new dataframe is returned (leaving the original input dataframe unmodified).
Returns
A dataframe identical to df but with an updated predicted_{target} column for each target, each one being the result of applying the thresholds and strategy specified by calibration_data to the appropriate yhat_probs columns.
Raises
Exception: Raised whenever an invalid important classes strategy is specified in the calibration_data dict.
from kortical.api import superhuman_calibration
new_df = superhuman_calibration.apply(df, calibration_data, in_place=False)
# score
This function prints automation/accuracy statistics pertaining to the predicted_{target} columns contained in df, as well as an automated f1 table, both overall and at a class-specific level. Also returns a dictionary containing more extensive information for processing by the user.
Inputs
df- The dataframe containing the predictions which should be scored. This should contain the relevantpredicted_{target}column(s).calibration_data- the thresholds that you wish to apply; this is the dictionary returned fromsuperhuman_calibration.calibrate(see above).
Returns
A dictionary containing overall automation metrics, class-specific automation metrics, f1-metrics over the entire dataset (both overall and class-specific) as well as f1-metrics over the subset of the dataset that has been automated (again both overall and class-specific).
from kortical.api import superhuman_calibration
metrics = superhuman_calibration.score(df, calibration_data)
The returned dictionary is structured as follows:
{
'automation_overall': {
'automation': 0.9,
'accuracy': 0.8
'for_review': 0.1
},
'automation_per_class': {
'class1': {
'automation': 0.9,
'accuracy': 0.8,
'for_review': 0.1
}
... all classes that can be automated
},
'f1_for_automated_rows': {
'weighted_average': {
'precision': 0.9,
'recall': 0.8,
'f1_score': 0.8,
'count': 1000
},
'classes': {
'class1': {
'precision': 0.9,
'recall': 0.8,
'f1_score': 0.8,
'count': 1000
}
... all classes that can be automated
}
},
'f1_for_all_rows': {
'weighted_average': {
'precision': 0.9,
'recall': 0.8,
'f1_score': 0.8,
'count': 1000
},
'classes': {
'class1': {
'precision': 0.9,
'recall': 0.8,
'f1_score': 0.8,
'count': 1000
}
... all classes including non automated
}
}
}