# API Playground
Each model deployment in a Kortical model has an API Playground page which provides a simple UI for the user to send requests to the model deployment's predict endpoint. It allows the user to experiment with different input parameters to the model. The predicted labels as well as information about label probabilities from the response are displayed on this page.
The API playground has a simplified version and a raw HTTP version. This is shown in the following sub-sections, for a model trained with the titanic dataset.
# Simplified
This mode provides a form to fill in the parameters to the model and get a prediction. This is displayed with the predicted probability. In this case, this person was not likely to survive.
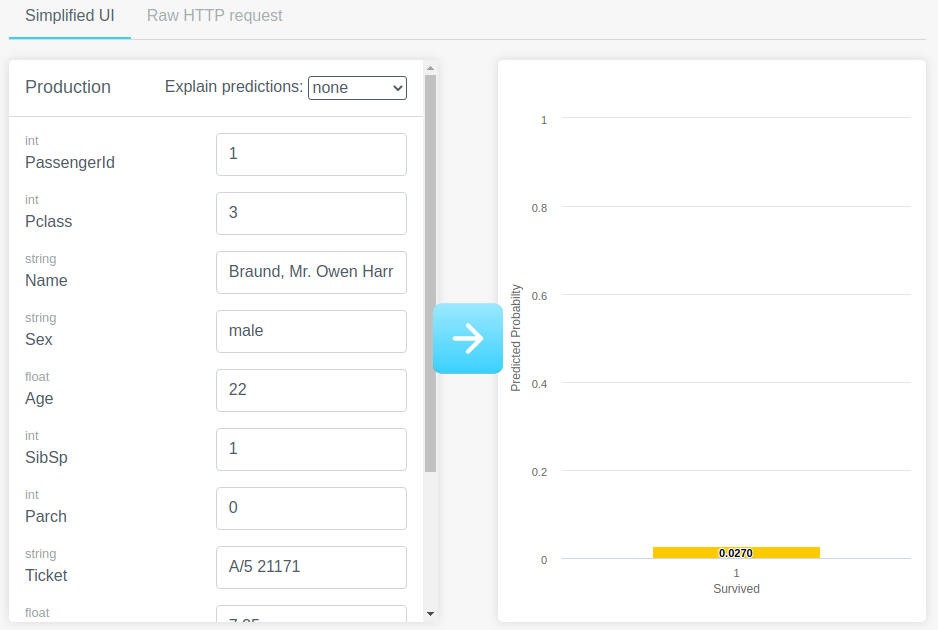
If we wanted to get explanations for why the model predicted this, we can set this dropdown to a value that is not none,
and re-run the prediction. The options are fast, accurate or exhaustive. For more information the differences between
these modes of explanation, please see this page. Here, we have selected
fast.

This time, the endpoint will return the prediction as well as explanations for the prediction.
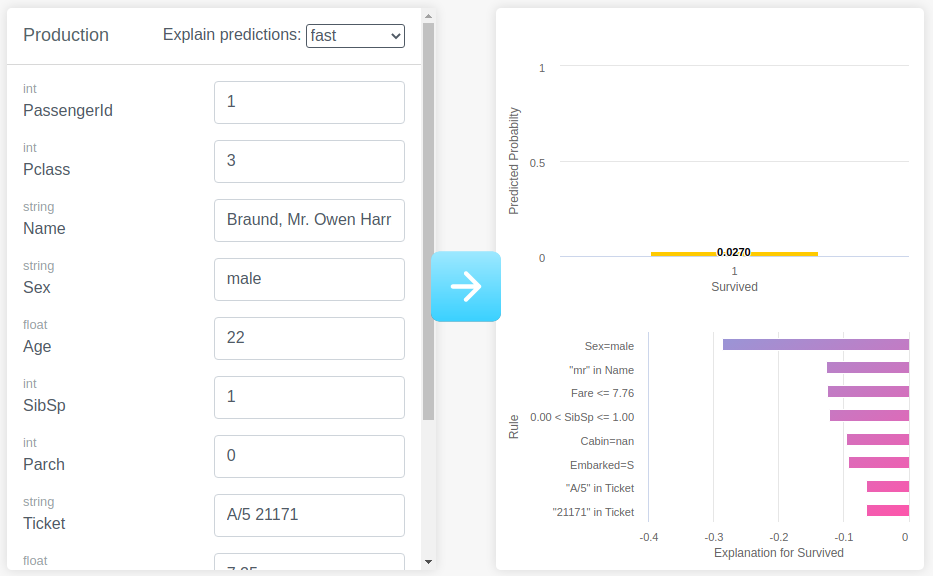
This now tells us that the model predicted a low probability of survival for this person as his sex was male.
Note
For more information about row explanations, please see the documentation.
# Raw HTTP
Raw HTTP mode has a similar layout to the simplified mode, but lets advanced users send requests as raw JSON through the form. The full response and the HTTP status of the request are displayed in the text area on the right.
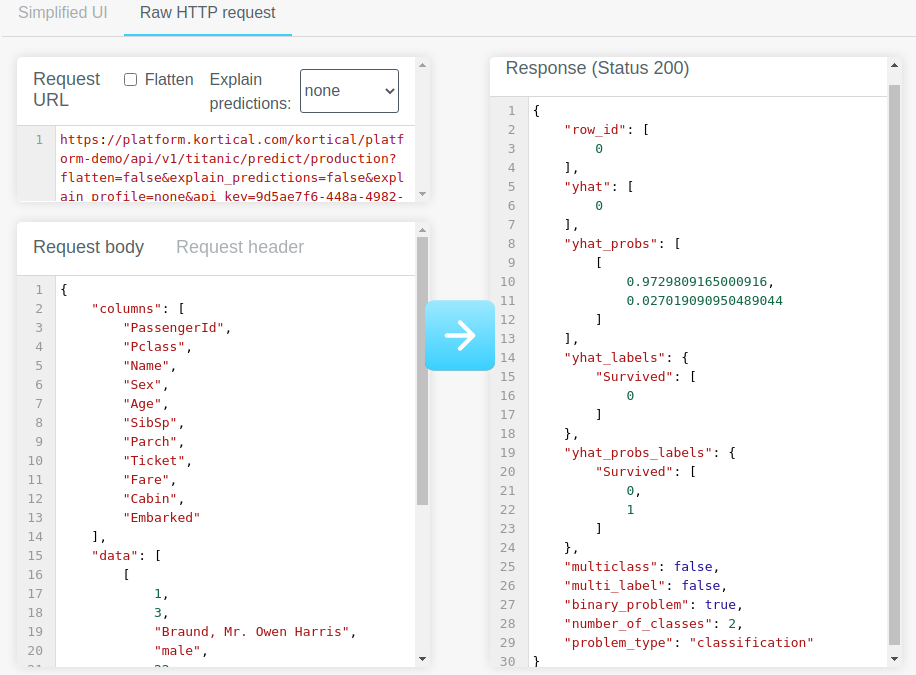
This mode also allows users to set the request headers. By default, this only contains the Content-Type, as this must be set.
when a request is sent where the user has asked for explanations, this will be part of the response JSON.
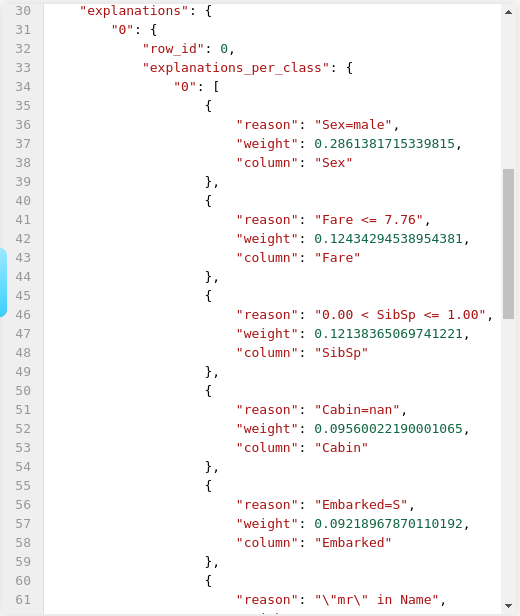
# The flatten parameter
One of the request parameters for the predict API endpoint is called flatten. If this is specified to be true, the
response JSON will be in a 'flat' format. This means that the response JSON can directly be loaded into a pandas
dataframe using its built-in read_json method.
WARNING
When calling read_json to achieve this, the parameter orient='split' must be set. Please see the example below.
import requests
import pandas as pd
predict_url = '<your predict url>'
request__input_data = pd.read_csv('/path/to/input/csv')
response = requests.post(predict_url, data=request_input_data)
response_df = pd.read_json(response.text, orient='split')
If flatten is not specified or its value is set to false, the shape of the response JSON will be different
and some extra keys will be included.
For the request JSON example we saw in the previous section, this is the response when flatten=true.
Each list in data is a row that corresponds to the indices in index and each element in each data list corresponds to
the column headers in columns.
{
"columns": [
"PassengerId",
"Pclass",
"Name",
"Sex",
"Age",
"SibSp",
"Parch",
"Ticket",
"Fare",
"Cabin",
"Embarked",
"row_id",
"yhat",
"yhat_probs",
"predicted_Survived"
],
"index": [
0
],
"data": [
[
1,
3,
"Braund, Mr. Owen Harris",
"male",
22,
1,
0,
"A/5 21171",
7.25,
null,
"S",
0,
0,
0.027019091,
0
]
]
}
When flatten=false, the response looks quite different. It has extra keys like problem_type and number_of_classes.
Each label in yhat corresponds to each row that was sent for prediction. The corresponding item in yhat_probs lists
the yhat_probs for the negative class and the positive class respectively. The corresponding yhat_labels item contains
a list of predicted labels and the yhat_probs_labels contains all the possible labels for that row.
{
"row_id": [
0
],
"yhat": [
0
],
"yhat_probs": [
[
0.9729809165000916,
0.027019090950489044
]
],
"yhat_labels": {
"Survived": [
0
]
},
"yhat_probs_labels": {
"Survived": [
0,
1
]
},
"multiclass": false,
"multi_label": false,
"binary_problem": true,
"number_of_classes": 2,
"problem_type": "classification"
}
For a more comprehensive detailed explanation of the predict API specification can be found here.
WARNING
Toggling the flattened parameter is currently only supported in raw HTTP mode in the API playground.