# Predict API with Python
The Kortical Predict API is easy to use with the pandas (opens new window) Python library. A Python code snippet to run prediction requests
against a model can be found on the Code Snippets page.
Here is an example of such a Python code snippet. This is calling a model that has been trained on the titanic dataset. Based on passenger details, the model is trying to predict if a passenger survived or not when the ship sank.
import pandas as pd
import requests
api_key = '2664ccb9-7ac0-4bdd-b768-4af3d63b7c52'
predict_url = 'https://platform.kortical.com/kortical/platform-demo/api/v1/titanic/predict/integration?flatten=true&explain_predictions=false&api_key={}'.format(api_key)
num_rows_per_batch = 2000
def kortical_predict(df_in, drop_index_columns=True):
df_in = df_in.reset_index(drop=drop_index_columns)
df_out_batches = []
for i in range(int(df_in.shape[0] / num_rows_per_batch + 1)):
batch_size = min(num_rows_per_batch, df_in.shape[0] - i*num_rows_per_batch)
if batch_size > 0:
df_as_json = df_in[i*num_rows_per_batch:i*num_rows_per_batch+num_rows_per_batch].to_json(orient='split')
response = requests.post(predict_url, data=df_as_json, headers={'Content-Type': 'application/json'})
if response.status_code != 200:
raise Exception("Request failed, status code: [{}]\\n\\n{}".format(response.status_code, response.text))
response_df = pd.read_json(response.text, orient='split', convert_dates=False, dtype=False)
df_out_batches.append(response_df)
df_out = pd.concat(df_out_batches)
return df_out
df = kortical_predict(pd.read_csv('data/to_predict.csv', low_memory=False))
df.head()
As you can see, the df_in can easily be converted into the data for the request by simply converting it to JSON using
the pandas built-in to_json function. The kortical_predict function expects df_in to contain all the columns
that the original model has been trained on. The shape of df_in before it is passed into kortical_predict should look
like this.
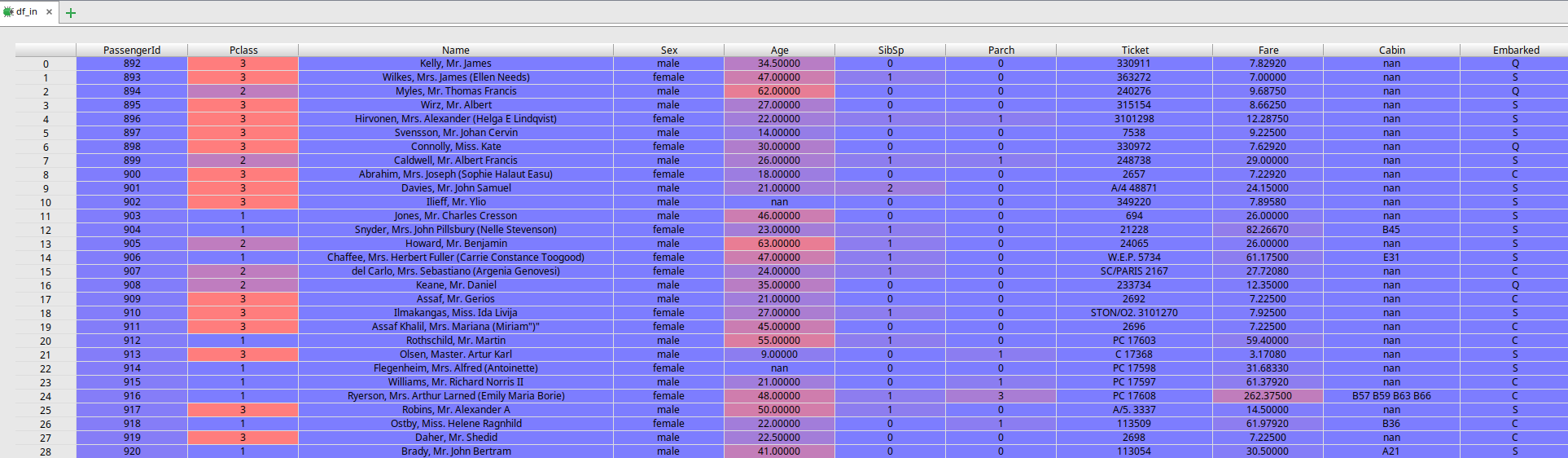
The columns match what the model expects. The dataframe df_out, which has been created from the response text
using pandas built-in read_json function, will have the same shape as df_in, but with extra columns from the model:
row_idyhatyhat_probspredicted_Survived
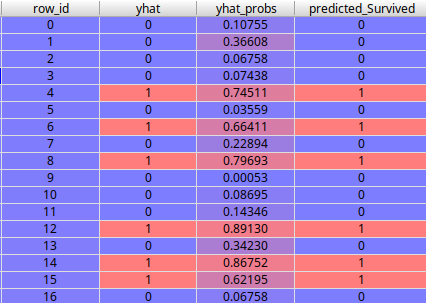
Note
The original column the model was trained to predict was called Survived, so the column with the predictions is called
predicted_Survived.
# Row Explanations
In the predict URL, if we had set the explain_predictions request argument to be true, the dataframe that we parse from the
response data will contain a bunch of extra columns with explanations for the models predictions.

Note
All the column names for the reasons end with [1] because these explanations are with respect to the positive class
(this is a binary classification problem), which is 1 (Survived=1).
This is is a dataframe that has been returned but the above kortical_predict function, where we have asked the model for
explanations, by setting these values in the request arguments.
explain_predictions=trueexplain_profile=fast
df_in in this case had 5 rows. For each row, the value represents the extent to which the reason (i.e. the column header)
contributed to the predicted class.
- If the value is positive, then the reason contributed its scalar amount towards the positive class, which in this case is
Survived=1 - If the value is negative, then the reason contributed its scalar amount towards the negative class (
Survived=0) - If the value is 0, this reason did not have an impact on this rows label.
Note
For more information about row explanations, please see the documentation.
Let's look at an example of row explanations for a multiclass model. These are predict explanations for a model trained on the IRIS dataset. The model is trying to predict the species of a flower based on numerical information about the dimensions of the flower.
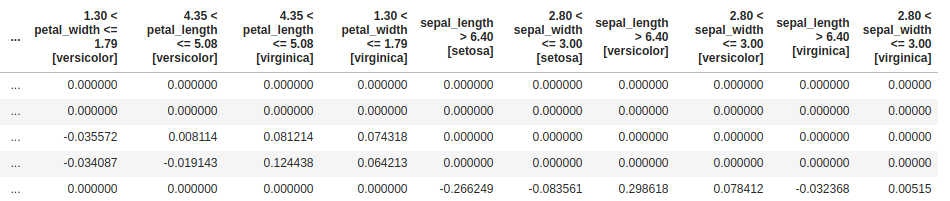
Here, the column names end with the class (e.g. [setosa]) that the explanation is with respect to. In this case:
- If the value is positive, then the reason contributed its scalar amount towards the class indicated in the brackets.
- If the value is negative, then the reason detracted its scalar amount away from the indicated class.
- If the value is 0, this reason did not have an impact on this rows class label.