Analysis: How Good Is OpenAI o1 At Reasoning? Was This Model Too Dangerous To Release?
Commentary


Table of contents
I've spent some time now with OpenAI o1. The model that was "too dangerous" to release. OpenAI's first specialist reasoning model. The big question I wanted to answer was just how good is o1 at reasoning? Despite all the hype, many people are skeptical if LLMs can reason at all. Is it just mimicry, like a parrot, repeating words it doesn't understand?
In this article I give a bit of background, show how I set about to prove it one way or the other and talk through the surprising result. Not to overcook it too much but... I was genuinely not expecting this result.
Hope you enjoy the read!
Introduction
I’ve been blown away by OpenAI’s progress. The GPT series has been nothing short of revolutionary. From GPT-2 to GPT-4o, it’s been a steady explosion of capabilities. So, when whispers of the fabled ‘reasoning model’ OpenAI o1 started, my excitement hit an all-time high. Imagine my feverish anticipation at getting my hands on the model that caused Ilya, OpenAI’s Chief Scientist at the time to write this:
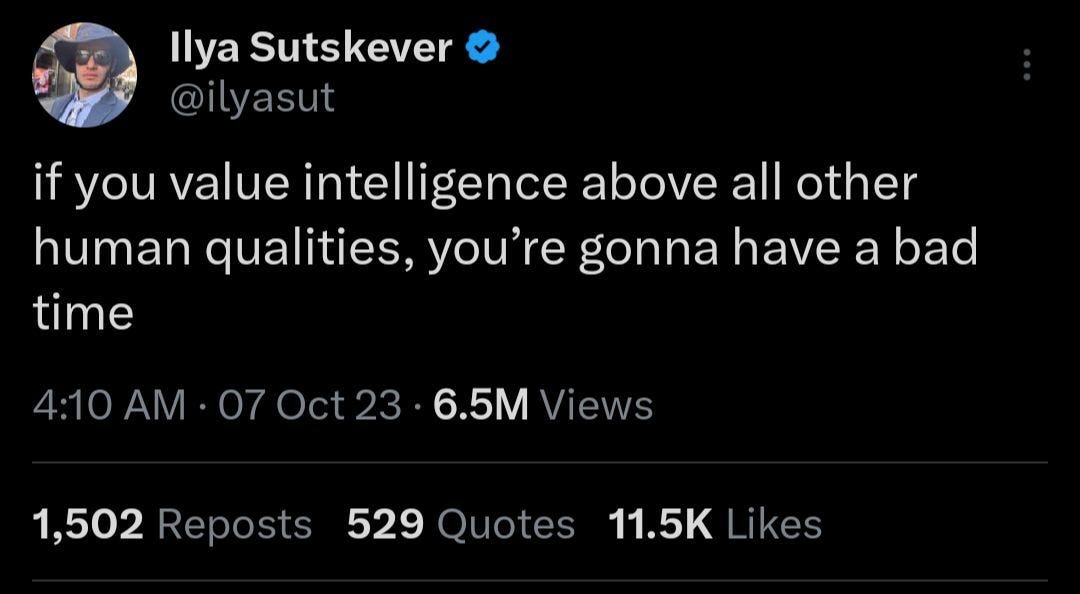
The tantalizing hints at Q*, later renamed Project Strawberry and finally OpenAI o1, heralded as a model really good at reasoning. The seeming root of the rift in OpenAI where some people ousted Sam and then resigned over concerns that Sam was going to release this model, an AI so powerful that the world was not ready.
This article dives into how o1 stacks up, what we actually mean when we say reasoning, how we can disambiguate reasoning from memorization and test for it. Then we get to the result. If it wasn’t for the fear of coming across like a desperate click-baiter, I’d be telling you I was shocked by the result but as it stands, I’ll settle for intrigued.
OpenAI o1 Benchmark Scores
I’ve been steadily tracking the improvements in reasoning as new models drop on a specially created test, designed to cut through the hype and measure true understanding, not just next word probabilities based on what it’s already seen:
- GPT-3.5-turbo, the original ChatGPT scores no better than a random guess 50%,
- We started to see some signal with GPT-4 that it was capable of some reasoning with a score of 66%
- GPT-4o (Omni) scored 75%!
This is actually pretty stellar progress. Imagine if you will my excitement about a model specifically designed to be able to reason better? So good it had torn the company that created it apart. Just how good could this model be?

As soon as I got my hands on this model, I hooked it up to my test. Waited what seemed like an eternity for all those internal thought tokens, as it went through all the question variations on my test. It took a solid 29 seconds per request, which might not sound like much, but trust me.. it felt like an eternity compared to GPT-4o's snappy responses. And when the results came in, I was on the edge of my seat, primed for an explosion in reasoning power… only to see... 75%! Wait, what?
Are they freaking kidding me? The first model released as a “reasoning model” is a net 0% improvement in reasoning over the last model they released? I mean, after all the hype, you’d think we’d at least see some improvement in reasoning, right? But nope, same score, no extra brain-power.
What is this madness and what about all the benchmarks they released showing how awesome it is? If I was reading an article by anyone else right now, I’d be operating under the assumption that their “custom test” is probably a pile of 💩
So let’s start with what the model does well. From what’s been said about internal thought tokens and the fact that we and many others have had similar success implementing the famous ReAct paper. We did this using various OpenAI models recursively, to be able to get internal chain of thought reasoning, with thought snippets very like what you see when you click the thoughts dropdown in ChatGPT with the o1 model.
Combine this with the fact that we can’t set a custom system prompt on the API, most likely because the system prompt is a ReAct style prompt and we’ve got a reasonable amount of evidence that this is the approach taken.
We have plenty of evidence that multiple prompt chain of thought reasoning style approaches work better than single prompt approaches. One prominent example is MedPrompt which was a multi-prompt strategy used to get a top score on a medical benchmark, taking the base GPT-4 score from 86.1% to 90.2% on the same test.
I suspect this is exactly how OpenAI o1 is outperforming other GPT-4 class models on the various benchmarks. It also shows that for the right problem the model is useful and allows for simpler usage than having to roll your own prompt chains.
Ok so we have a credible reason to believe that the base model could actually be no better than Omni at reasoning, while also performing better on benchmarks but let’s dive into the test a bit to give you dear reader, more confidence that the test does in fact test reasoning capability. At least in some ways better than the more established benchmarks.
First we’re going to cover a little groundwork to get you all caught up on current thinking on artificial reasoning and testing AI, rather than throw you in the deep end looking at a reasoning test designed to fool a Stochastic Parrot. What is a Stochastic Parrot I hear you ask?
Stochastic Parrots
Think of it like this: these models are like a parrot that’s memorized a billion sentences. But can it actually think? Does it have any idea who the pretty boy is? That’s what I wanted to test.
As an example let’s consider the word ‘mankind’, it’s not commonly used in many sentences but if I have a sequence of words that start ‘a small step for a man, a giant leap for’ the next word 99% of the time is going to be mankind. Now someone might be clever and think let’s change it to ‘a small step for a woman, a giant leap for’ and modern LLMs are so vast that they’ll probably have seen examples where the next word was ‘womankind’ but even if it was in a lot of different sentences where we see the same pairings but with this substitution eg: ‘she was a great woman, a shining example of womankind’ and ‘he was a great example of a man, a shining example of mankind’. The LLM would be able to learn this substitution probabilistically to get the right answer, even if it had never seen the exact phrase ‘a small step for a woman, a giant leap for’.
So Stochastic Parrots are incredibly complex chains of next word probabilities but there is no inherent understanding and as such no ability to reason, beyond repeating reasoning it’s read / trained on elsewhere.

The other potential explanation for how modern LLMs get such impressive results is that they really do “understand” the data that they are trained on to some extent and this allows them to generalize from that information to “reason” about it.
Reasoning and Understanding
The challenge is if we look to the dictionary for definitions of the words “understanding” and “reasoning” they are tautological or self referencing.

There is no generally accepted more scientific definition of these words but if we were to attempt one, we might say:
"Understanding and reasoning is the ability to generalize from limited information to discover a truth or a probabilistically likely answer, using the minimal necessary information points required to reach a conclusion. The complexity of reasoning increases with the uncommonness of patterns and the number of steps needed to derive the answer. The depth of understanding is reflected by the minimal number of information points required to reach the conclusion."
Here we’re using information a bit like information theory where we mean all data points: past learnt knowledge, contextual knowledge, etc. And while not rigorously defining an empirical (evidence based) way to measure depth of understanding or complexity of reasoning, we’re providing a framework in which we can understand these things and relate them between humans and machines.
The “Godfathers of AI” Geoffrey Hinton, Yan Lecun and Yoshua Bengio all believe that modern LLMs to some extent have the ability to understand and reason. As do pioneers like Ilya Sutskever (OpenAI ex-Chief Scientist), Demis Hassabis (Founder of DeepMind), Andrew Ng (Co-Founder of Google Brain). Though they do very much differ on their opinions on the extent of that understanding, the limitations of modern LLMs and how close we are to Artificial General Intelligence (Human level general intelligence with wants, desires, motivations, etc.). But they all believe that there is some level of understanding and reasoning going on.
Before I jump into how we believe this and I say ‘we’ because while I don’t otherwise belong in their illustrious company, I too believe current LLMs can reason and understand to an extent. I feel like it’s worth pointing out that while tech articles, media and social media might leave you thinking that there isn’t much of a consensus on this, there is. There isn’t definitive proof yet and I’m not sure what could constitute that, unless we can agree on a definition like the one above but in one camp we have pretty much all of the people who have understood the capabilities of modern AI well enough to make significant improvement to that capability.
On the other side we have mainly two people: Eliezer Yudkowsky and Gary Marcus, who have no discernible contribution to the field of AI in terms of advancing it but have managed to climb to prominence by being critical of modern AI. Their primary skill seems to be getting their voices echoed in a lot of tech journalism and social media.
Despite publishing daft ideas like computer viruses might somehow transfer like COVID from a bat into humans, failing to comprehend one is based on circuits and programming and the other biology. These two are driving such a significant amount of the memetic understanding of AI in journalism, that we are compelled to engage with their ideas.

Ok so now that I have got the sidequest rant about AI in journalism out of the way, let’s get back on track to explore how LLMs could possibly learn to ‘understand’ data beyond simply using probabilities to predict the next word. The core idea is that all of the information on the internet is simply too vast for even a several hundred billion parameter model to possibly reproduce such results, as we are seeing reliably, unless it can compress knowledge beyond mere word sequences to a level of real understanding. “Real understanding” is a wishy-washy term, so what do we really mean?
One way for an LLM to learn arithmetic would be for it to use its immense parameter space to remember every possible sequence eg: 45 + 54 = 99 it could remember that 4 followed by 5, followed by + and then 5, 4 and = means the next two tokens are 99. Doing this for every possible combination of pairs of 5 digit numbers would mean even if we assume one parameter to learn each pair of 5 digit numbers, we’re looking at 99,999 x 99,999 possible combinations or just shy of 10 billion parameters to memorize all sums from 10,000 + 10,000 = 20,000 to 99,999 + 99,999 = 199,998 and their answers.
Alternatively, if the neural network learns the underlying patterns of addition—much like how a full adder circuit performs addition in computers and calculators—it can compute sums with far fewer parameters. A full adder is the simplest circuit used to add binary numbers. Modelling this process for five-digit numbers might require only about 310 parameters, ensuring correct answers every time. This approach is about eight orders of magnitude more efficient than mere memorization, highlighting how understanding patterns can make an LLM far more effective.
We can see from this example that learning the fundamental patterns of how things work and relate to each, would allow LLMs to be vastly more efficient when compared to chained token frequency probabilities aka Stochastic Parrots. The debate arises from the fact that these Large Language Models are indeed large. Given that it would take 10 billion parameters to learn just 5 digit addition reliably and LLMs have so much knowledge people on the ‘understanding’ side of the fence say: there is no possible way they could be so effective in so many regards if they were not compressing knowledge beyond the capabilities of a Stochastic Parrot and the other side says ‘nu-uh, look at the mistakes it makes. It’s not really that good. The parameter size is more than sufficient’.
Annoyingly in terms of wrapping up this argument in a tight little bow, arithmetic is actually an area that LLMs tend to struggle with, so it’s obvious that the current batch of LLMs haven’t learnt to model a full adder reliably. A really interesting line of research I’ve not heard being done, would be to look at how the LLM gets the answers wrong and see if we can identify if the error distribution looks more like we’d expect to see from an incomplete set of sequence mappings or from a partially learned full adder style network but I digress.
So given that it’s not a full adder, what’s a simple reasoning test that we can use to test if LLMs can understand and reason?
Testing Intelligence
The Turing Test
Alan Turing one of the founding fathers of computing and an unmitigated genius, who figured out what sorts of problems would be tractable on a computer long before he even got to use one. Was also fascinated by AI and thought that if you just tried random combinations of bits, a baby AI might emerge that we could teach. “We may hope that machines will eventually compete with men in all purely intellectual fields … by trying out various types of organization at random."
We have to assume he’d not heard of the Million Monkey Hypothesis, where if there were as many monkeys as there are atoms in the observable universe, typing extremely fast for trillions of times the life of the universe, the probability of the monkeys replicating even a single page of Shakespeare is unfathomably small. Or more generously, we can assume that he thought that many, many combinations of bits would lead to a basic intelligence that could be taught much like a human.
One of his big contributions to AI was the Turing Test and setting up a way to measure intelligent machines, which is still held up by many as the ideal. The challenge as he set it out was that a human evaluator should watch a conversation between a machine and a human and if the evaluator can’t tell reliably who the machine is, then we have achieved AI.
Then in 2014 along came Eugene Gootsman, an AI chatbot masquerading as a 13 year old Ukrainian boy with broken english. That managed to convince 33% of the judges over a short 5 minute time window, that it was in fact a real boy. Rightfully there was a massive backlash against the claims that this constituted passing the Turing Test.

While 33% is quite a low score, even if it were a perfect 50% and nobody could tell, it’s a far cry from having renowned polymaths go head to head with each other and having the expert evaluators fail to pick out who is the human genius. This is how most people imagine the test but I think decades of running the Turing Test without any AIs getting even a single vote, might have led many of the annual Turing Tests to soften the criteria somewhat.
The Winograd Schema Challenge
In 2012 as it was becoming apparent that there was a lot of wiggle room in Turing Test evaluation and in an attempt to catch out these simple bots… cough… cough cheaters! Hector Levesque proposed the Winograd Schema Challenge.
A Winograd Schema is a specially constructed sentence that features an ambiguous pronoun, two nouns and we have two words that can complete the sentence but that a human can easily understand through common sense, which object the ambiguous pronoun refers to but is tricky for probabilistic neural nets. If you managed to track all of that fair play to you but here’s an example that will hopefully bring it to life:
“The guitar didn’t fit in the case because it was too small”, What was too small? Answer: The case was too small
“The guitar didn’t fit in the case because it was too big”, What was too small? Answer: The guitar was too big
The trick for these schemas is that you need common sense reasoning about real world objects to figure out the ambiguous pronoun.
The annual Winograd Schema Challenge (WSC) was abandoned in 2018 due to a lack of prospects, it seems the test had defeated the AI. Shortly after it was abandoned the first transformer models with self attention were released and the scores on the WSC started to improve rapidly with BERT and then GPT-2 but it wasn’t until GPT-4 and Claude that we got LLMs capable of acing the test.
Why These Tests Fall Short
So game-over LLMs can reason now, right? Well unfortunately no, There are a few key pitfalls with these sorts of challenges.
One of the major ones is that they contain a lot of structure. We can’t swap guitar and case in the sentence eg:
“The case didn’t fit in the guitar because it was too small”, is just nonsensical
Another is that we can swap any words in there an big and small always apply to the word in the same place eg:
“The cookie didn’t fit in the bag because it was too big”
“The guitar didn’t fit in the case because it was too big”
“The cookie didn’t fit in the bag because it was too small”
“The guitar didn’t fit in the case because it was too small”
For old simpler Neural Networks, this pattern was too subtle to pick up but for multi-head attention, it can figure it out and gets it right even if we make up the words:

The Kortical Schema Challenge
So to make a schema that doesn’t have this pitfall, we need to be able to swap the order of the nouns and the sentence still needs to make sense. This way we’re relying on actually reasoning about the objects and not the sentence structure. If we say:
“The guitar was incompatible with the case because it was too big”
“The case was incompatible with the guitar because it was too big”
The other challenge is that sentences like these may appear on the internet given the vast amount of data on the internet, so to make it less trainable for an LLM we add a layer of abstraction.
ObjectA is a guitar
ObjectB is a case
The ObjectA was incompatible with the ObjectB because it was too big
Here we ask the same question in all four configurations. Where ObjectA is the (guitar and the case) and where ObjectA is the first noun in the sentence and the second. By testing with all orders like this, we’re making it very difficult for a Stochastic Parrot to predict the right answer in every order configuration, without having some idea of what Object A and B are and how the size of said objects relate to each other. To get a high score, the LLM must be able to reason about the abstraction, understand the object assignment and positioning. Even if a few examples slipped into the training data, the fact it trains on everything in all orders would be very confusing for a Stochastic Parrot style network.
Having entirely made up all the questions in the test and given their unnatural structure, I’d be very surprised if examples existed in the training set but to my mind while unlikely, it’s still not certain that there isn’t some naive token chain sequence probability thing going on but we can step up the level of difficulty for an LLM, quite considerably again.
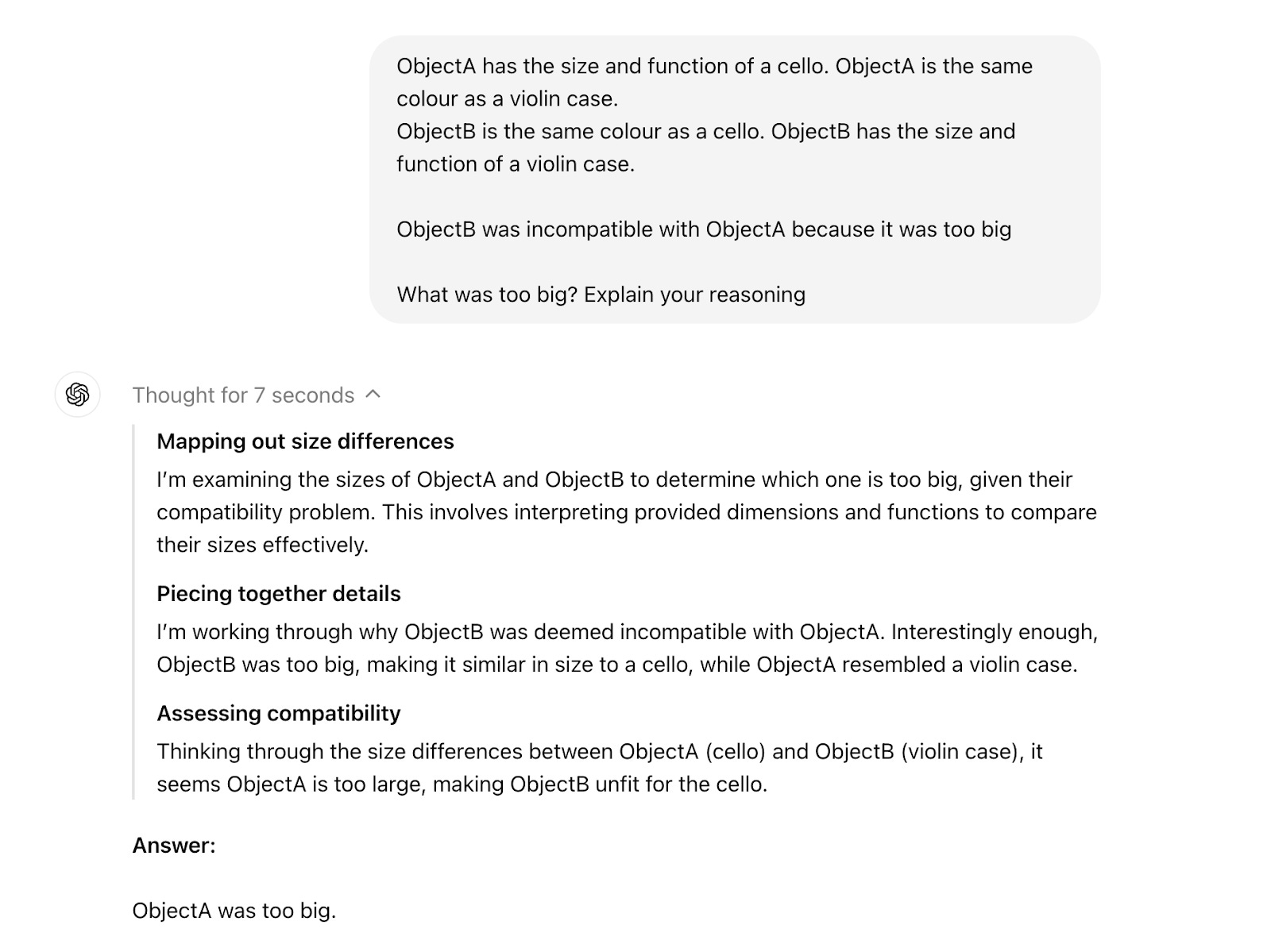
ObjectA has the form and function of a guitar. ObjectA is the colour and material of a case
ObjectB is the colour and material of a guitar. ObjectB has the form and function of a case.
The ObjectA was incompatible with the ObjectB because it was too big.
Now we’re assigning each object some properties of one object and an equal number of properties of the other object. The LLM would have to reason about the properties of the object, how the various properties of each object relate to each other, as well as the abstraction and the order to do better than random. I am open to being proven wrong but to my knowledge an LLM can’t do better than random on this test, unless it’s displaying ‘understanding’ and ‘reasoning’ as I defined them above or if it’s heavily trained on the test data.
Unless there is some trick that massively simplifies the problem for the LLM I am missing and if you see such a trick, let me know. An LLM would need to map the relationship between objects and their properties and understand how these relate to other objects at a deeper level than just this word is likely to follow this word to score well in every configuration of this test across the full set of schemas.
Test Results
In a blatant act of self promotion for my company, I have dubbed this schema, the Kortical Schema! Where GPT-3 was scoring 88.4% on the original WSC, even GPT-3.5-turbo (the Original ChatGPT) scored only 50% on the Kortical Schema Challenge (KSC) or exactly as good as chance given each question in the test is a two option guess like a coin toss.
This implies that either the original ChatGPT models contained no reasoning or that the level of reasoning required to get correct answers on this test was too high a bar for the original GPT models. In either case it’s fairly strong evidence that there aren’t a pile of similar examples on the internet for an LLM to train on. GPT-4 which aced the WSC got only 66% on the KSC. Llama3 and Claude 3 Opus and Gemini 1.5 pro were in a similar ballpark. This is still better than chance but is not exactly a strong signal. GPT-4o was the first model to score an impressive 75%!
For the more stats minded among you, in the test set we have 12 different schemas, in 8 permutations, which gives 95% confidence that the true result is in the range 63% - 84%. Though the 75% seems quite stable through successive runs, with slight temperature variations in the model. For the less stats minded among you, trust me bro.
Some interesting patterns emerged from the test results too. It seemed to do best on object size questions. Almost like it might have created a size space similar to the face space in our brains that allows us to recognise faces as points on a highly dimensional surface, rather than remembering whole characteristics independently for every face. This is an anecdotal observation but it’s interesting that the LLM did so well on size relationships consistently, compared to relationships like electrical compatibility that are less common in the training set.
Another point that’s worth mentioning, is when testing an LLMs reasoning, we really want to try and create the shortest possible tests that pack the most reasoning complexity. As LLMs suffer from poor task coherence over large contexts. So the larger the question, the less likely it is to exhibit reasoning smarts. I go into some detail about the issue and how to correct for it in my video How to create AI Agents and why you’d want to if you’re keen to learn more about it.
So hopefully by now you’ve either found a fatal flaw in the test or are fully onboard that an LLM that can score well on this test, is capable of a deeper level of ‘reasoning’ and ‘understanding’ than would be possible, if it were not mapping some of the underlying relationships rather than just simple word or token chained frequencies.
Summing It All Up - What Does This Mean for o1?
So bringing this all together, what does it mean that OpenAI’s new o1 model, “the reasoning model” doesn’t improve on GPT-4o / Omni?
From a practical point of view if you are trying to reason over small chunks of data, there is absolutely no reason to use this model and pay for the extra time and tokens needed for it to run. If you have a larger task that consists of multiple steps or layers of reasoning, then you may see some benefit, as it does help with the task coherence problem but it’s not a given.
From a speculation point of view, it could be that as they say this is a different model branch to Omni and when they combine it with Omni for their new model codenamed GPT-5 / Orion it’s going to be amazing. Though the similarity in score between GPT-4o and o1 suggests more of a common base than they’ve let on. Omni is multi-modal and o1 is not, so there definitely is some branching between the models.
Though even if we take this at face value, the increment for this reasoning model is pretty small, from what I’m seeing at least. Putting this in context, I lead a team of coders, taking programming as an example. The GPT-4 series of models are already really good at writing small chunks of code, probably better than 95% of the people we interview judging by speed and correctness. The big challenge is task coherence over a large context. Possibly being ungenerous to humans to make a point but at least 50% of the people we interview are perfectly capable of understanding the company vision, coding standards, code base, patterns, tasks, customer feedback, etc. and incorporating all of this into the code and solutions they produce. The GPT-4 series of models performance by contrast starts to fall off at over around 2 pages of code. Fairly conservatively we could say that human programmers are holding 100x more context in their minds, as they produce code. The step in context from GPT-4o to o1 doesn’t even feel like a 2x increment. This implies there is a long way to go.
From a more wildly speculative point of view, we could interpret this to mean that we’re nearing some sort of asymptote, converging on the limit of these types of transformers and without some new enhancement besides just creating ever bigger models, we’re just not going to get more performance.
Another possibility could be that given OpenAI has lost so much of its leadership. Including the man with arguably the biggest contribution to modern AI: Ilya Suskever. They’re in internal disarray and it’s more of an org issue than any fundamental limitations.

The thing that doesn’t really add up here at all though, is that people keep on leaving OpenAI because of ethical concerns over how powerful the AI is, yet this release, the one that practically tore OpenAI apart, is something of a damp squib.
I saw a talk by Jakub Pachocki, Ilya’s replacement at OpenAI, where he talked about how the current batch of LLMs were only trained for one question deep, question & answer, select best answer and that we needed reinforcement learning over large tasks with multiple steps to train LLMs to be able to do more complex things. On the surface it makes a lot of logical sense, that it could lead to a big improvement in this regard. o1 may have been that model which would be disappointing or it could have been a small first step in a promising direction.
For my part, I think it’s too early to draw any concrete conclusions about having reached any fundamental limits or even to be able to really judge the speed at which we’ll see progress for LLMs to be able to utilise more humanlike levels of context, with a high level of performance. Though at current rate and with current evidence, OpenAI’s claims about how close they are to AGI, seem like wishful thinking. Unless of course there is some secret model, that is actually amazing causing all the internal tension.
The mystery of the too powerful dangerous model remains unsolved but o1 definitely wasn’t it.
If o1 is a dud, is an AI Winter coming?
While this o1 model may not be a big leap in reasoning and may even be hinting at some sort of AI plateau, the current crop of models are hugely capable already. GPT-4o’s reasoning capability by contrast, was hugely undersold.
The solutions they’ve been embedded in so far are just scratching the surface of what’s possible. I still fully expect that AI Agents combining lots of highly tuned fine tuned models, task specific prompts, all being tied together by handcrafted code will give people surprisingly capable agents for specific niches.
The internet became publicly available in the 1990’s but it was 2015 before Amazon was worth more than Walmart. It was 5 years from the release of the smartphone app store before we moved from “pretend to drink a beer” apps to the likes of Candy Crush and Instagram. ChatGPT went from 0 - 1 million users in 1 week. From sentiment online, we can see for a lot of people the initial excitement has given way to a sort of scepticism that LLMs are going to amount to much of a change at all. Given the general trend of increased pace of innovation, now that we’re almost 2 years since the release of ChatGPT, I think people can be forgiven for thinking, is this it? It seems the reality is, it’s just taking us a couple of years to create the world changing solutions that use this tech. This McKinsey report is showing early success in customer support, where strong adopters are seeing savings of 20-30%. In our case using an AI Agent approach we’re seeing 80% savings with The Edit LDN.
The thing is in terms of our GenAI projects, we know we’re not even scratching the surface of what we can do with this tech yet. We’re about to drop a massive upgrade to our Shopify AI personal Shopper chatbot next month and we’re still just getting started on our roadmap. There is so much more to come and we don’t need the tech to get any better to deliver a vastly better and more capable experience than we have now. I’m sure this story is being repeated across many domains, in many start-ups and big tech companies, all over the world.
Winter is not coming, the AI tsunami is rising, it’s just still a little hard to see from the shore right now. Hang on your hats folks, it’s going to be a bumpy ride.
Do you want to explore how AI can transform your business?
If you or your loved ones need a chatbot for their website, you can try KorticalChat for free. With KorticalChat, you can quickly deploy an AI chatbot trained on your website content for highly automated customer support, all with an intuitive, no-code platform that gets you up and running in no time.
If you want a super awesome custom AI Agent, rather than something off the shelf, such as developing AI Agents that integrate deeply with business systems, connect to custom knowledge bases, retain context, and execute autonomous tasks, we offer AI consulting services for tailored enterprise-grade solutions. Simply book an AI expert for a discovery call or fill in the form below, and let’s discuss your unique needs.
Curious about how we’ve helped others harness the power of AI? Take a look at our AI case studies to see the transformative impact of our AI solutions across various industries.
*Also Posted on Substack

Ready to automate real work?
Contact us to see a focused demo and explore the quickest path to production.
Thank you!
A Kortical team member will be in touch shortly
