Dropping Features Early: Smart, Time Saving and Efficient or Amateur, Bad Practice and Lazy?


Table of contents
One of the more suprising features of Kortical for many data scientists is that it offers to drop columns out of the box. The challenge comes from the fact that many of the ways people might try to approach this, don't actually work and so are considered bad practice. Some people might not have heard of Kortical yet and so have a healthy dose of skepticism when we say don't worry we've cracked it, trust us.
What follows is a worked example of the approaches people have assumed we've taken why they don't work and our actual approach, which saves time and helps make better models.
Creating the dataset
First we create a dataset where we have column interactions that predict the target but are individually uncorrelated to the target. This can be accomplished simply by using XOR. So now XOR and A combined predict the Target and B and C are noise but all of the columns have the same profile as noise.
We also add a little noise to the target to make it a bit closer to what we'd tend to see in the real world.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
np.random.seed(0)
num_rows = 20000
df = pd.DataFrame({
'A': np.random.randint(0, 2, num_rows),
'B': np.random.randint(0, 2, num_rows),
'C': np.random.uniform(size=num_rows),
'Target': np.random.randint(0, 2, num_rows)
})
df['XOR'] = df.apply(lambda row: int(row['A']) ^ int(row['Target']), axis=1)
df['Target'] = df['Target'].map(lambda x: x if np.random.uniform() < 0.5 else np.random.randint(0, 2))
train = df[:num_rows//2]
test = df[num_rows//2:]
train.to_csv('drop_features_train.csv', index=False)
test.to_csv('drop_features_test.csv', index=False)
df.head()
Dropping features based on correlations
sns.heatmap(train.corr())
plt.show()
Above the light colours show that every feature is perfectly correlated to itself but the darker colours indicate no correlation to any other feature. If we drop features based on correlations, we'll drop all the features because all the columns are all individually uncorrleated to the target.
This is a pretty straightforward example of why we can't use correlations to drop features.
Dropping features based on feature Importances
rf = RandomForestClassifier()
rf.fit(train[['A', 'B', 'C', 'XOR']], train['Target'])
print('Test set Score: {:.2f}'.format(rf.score(test[['A', 'B', 'C', 'XOR']], test['Target'])))Test set Score: 0.63
print(f"Feature Importances: A: {rf.feature_importances_[0]:.2f}, B: {rf.feature_importances_[1]:.2f}, C: {rf.feature_importances_[2]:.2f}, XOR: {rf.feature_importances_[3]:.2f}")Feature Importances: A: 0.15, B: 0.00, C: 0.75, XOR: 0.10
Here we train a random forest on the training set and predict on the test set. We can see that the model is predicting better than 50/50 but when we look at the feature importances, it's quite misunderstood the importance of different variables and if we dropped all the variables with 0.15 or less importance we'd lose all our signal and be overfitting on noise.
This would create a terrible model, that's right about half the time because it's a coin toss. So we don't want to remove features based on feature importances.
rf = RandomForestClassifier()
rf.fit(train[['C']], train['Target'])
print('Test set Score: {:.2f}'.format(rf.score(test[['C']], test['Target'])))Test set Score: 0.50
Dropping features using Boruta
from boruta import BorutaPy
X = train[['A', 'B', 'C', 'XOR']].values
y = train['Target'].values
rf = RandomForestClassifier()
rf.fit(X, y)
feat_selector = BorutaPy(rf, verbose=1)
feat_selector.fit(X, y)
# call transform() on X to filter it down to selected features
X_filtered = feat_selector.transform(X)Iteration: 1 / 100
Iteration: 2 / 100
Iteration: 3 / 100
Iteration: 4 / 100
Iteration: 5 / 100
Iteration: 6 / 100
Iteration: 7 / 100
Iteration: 8 / 100
Iteration: 9 / 100
Iteration: 10 / 100
Iteration: 11 / 100
Iteration: 12 / 100
Iteration: 13 / 100
Iteration: 14 / 100
Iteration: 15 / 100
Iteration: 16 / 100
BorutaPy finished running.
Iteration: 17 / 100
Confirmed: 0
Tentative: 0
Rejected: 4
Boruta was a suggested package in the auto feature selection space from a commenter. I'm not very familiar with it but from the results above it choses to reject all of the columns, which obviously makes it an unsafe choice.
Dropping features using Kortical
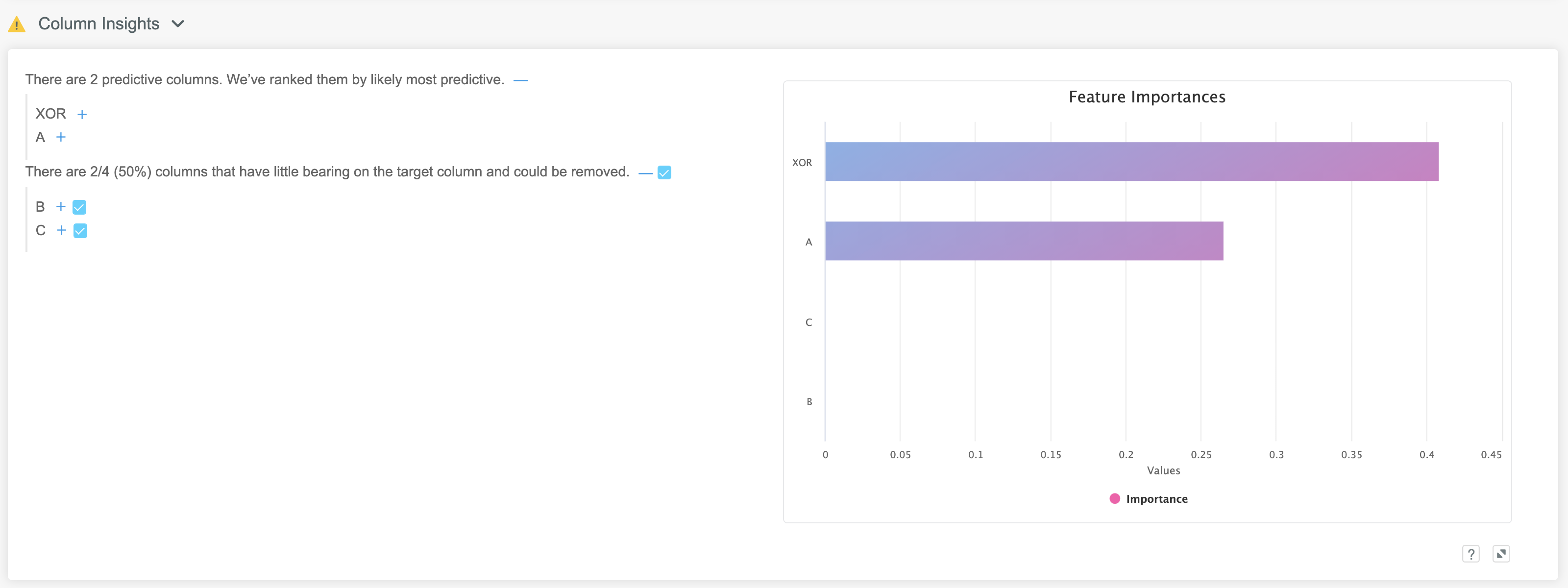
Once we take the training data and upload it to Kortical and select a target, you can see Kortical is able to figure out that columns A and XOR are the ones we need, by using a much more sophisticated selection process and if we use these to build our model having removed some of the noise, then we get the best results.
rf = RandomForestClassifier()
rf.fit(train[['A', 'XOR']], train['Target'])
print('Test set Score: {:.2f}'.format(rf.score(test[['A', 'XOR']], test['Target'])))Test set Score: 0.74
By reducing the irrelevant columns, we're giving the model more of a chance to find the signal in the columns that do have signal and so we get a 17% improvement over a base model trained on all columns.
Even when using distributed cloud scale machine learning, Kortical can take a while to complete this process for large or complex datasets but it is worth waiting for it to complete, for best results.
Summary
What this shows is that the general advice is correct, don't use correlations to drop features and don't use feature importances to drop features either but there are safer methods that can generalise well. Kortical's feature selection is the best we have come across, you can read the technical paper with a deeper literature review and get free access to a working version of the algo here
If you can drop features safely, it can help:
- Reduce model train times
- Reduce the amount of wasted effort exploring irrelevant features
- Improve model results
In fact our meta-analysis of how top kagglers are acheiving best results, showed that the majority are dropping features. This example showed a 17% model performance boost, from dropping irrelevant features which tells you why they spend time on this.
Now some caveats are that Kortical is not perfect but we've tuned it against a wide range of diverse datasets and it seems to perform well.
If you're a researcher doing a PhD dealing with very complex subtle interactions you might want to avoid the feature dropping recommendations, untick it in Kortical and take the time to explore all your features and their potential interactions in great detail.
If you're in industry, don't have years to analyse your data and are looking for a reasonably robust way to accelerate your data exploration, model development and produce better models then this is probably for you.

Ready to automate real work?
Contact us to see a focused demo and explore the quickest path to production.
Thank you!
A Kortical team member will be in touch shortly
